この記事はImaizumi Lab Advent Calendarの9日目です。
なお記事の投稿は13日の模様。
更新履歴
2020/12/13 投稿後にpeepdfのマルウェア検知機能について書き忘れていたことに気づいたので追記
はじめに
前回に引き続き、PDFの内部構造を見ていきます。
前回の記事はこちらです。
今回のトピックは、PDFを解析するのに便利なツールの紹介です。
前回の記事でPDFの構造がどうなっているかをみていきました。構造を詳しく見ていくと面白そうですが、PDFのインダイレクトオブジェクトの参照関係を手作業で探ったり、出てくるキーワードをカウントしていくのは大変ですよね。そこでツールの出番です。
紹介するツールは全てPython製で面倒なインストールなど不要なので、是非お手元のPDFで試してみてください。
(Pythonは2系と3系の両方が使える必要があります。peepdfが2系でしか動かないためです)
PDFiD
DidierStevensSuite/pdfid.py at master · DidierStevens/DidierStevensSuite · GitHub
PDFの特定のキーワードを抽出し、数を表示してくれるツールです。
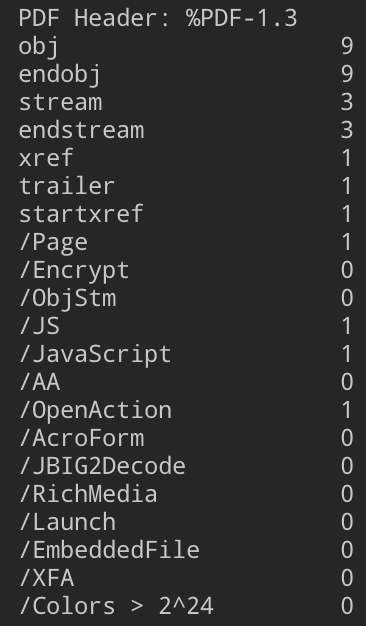
PDFの機能を悪用したマルウェアでは特定の機能が使われることが多く(/JavaScript、/OpenActionなど)、このツールで調べることでそれらの機能が使われているかを簡単にチェックすることができます。
pdf-parser
DidierStevensSuite/pdf-parser.py at master · DidierStevens/DidierStevensSuite · GitHub
非常に高機能なPDFパーサです。
先ほど紹介したPDFiDと似たような統計出力機能もあります。*1
実行してみる

オプションなしで実行すると、
- オブジェクト番号と世代番号
- インダイレクトオブジェクトの種類
- 参照関係
- ディクショナリの内容
が表示されます。
ファイル全部ではなく特定のインダイレクトオブジェクトだけを見たい場合は、「-o n (nはオブジェクト番号)」と指定します。
その他できること
-yオプションでYARAルールを引数に取ることで、ルールに基づきPDFが悪性かどうかを検知できます。*2
-sオプションで「-s hogehoge」のように指定すると、hogehogeを含むオブジェクトを抽出できたりします。
ちょっと面白いのは、-gオプションを用いるとパース対象のPDFファイルを生成するPythonプログラムを生成します。どこで使うのかはちょっとわかりませんが...
peepdf
Pythonのバージョンが2系でしか動かないため注意が必要です。*3
特定のライブラリがないと怒られるかもしれませんが、ここに書いてあるオプションはそれらのライブラリなしで実行可能なので、無視しても大丈夫です。*4
実行してみる

オプションなしで実行すると、統計情報が表示されます。
tree表示
python peepdf.py hoge.pdf -f -C tree
上記のコマンド*5で、参照関係を表した木構造を表示させることができます。カッコの中はオブジェクト番号です。試しにオブジェクト番号が2のインダイレクトオブジェクトを、出力したtreeとファイルデータの両方で見てみましょう。
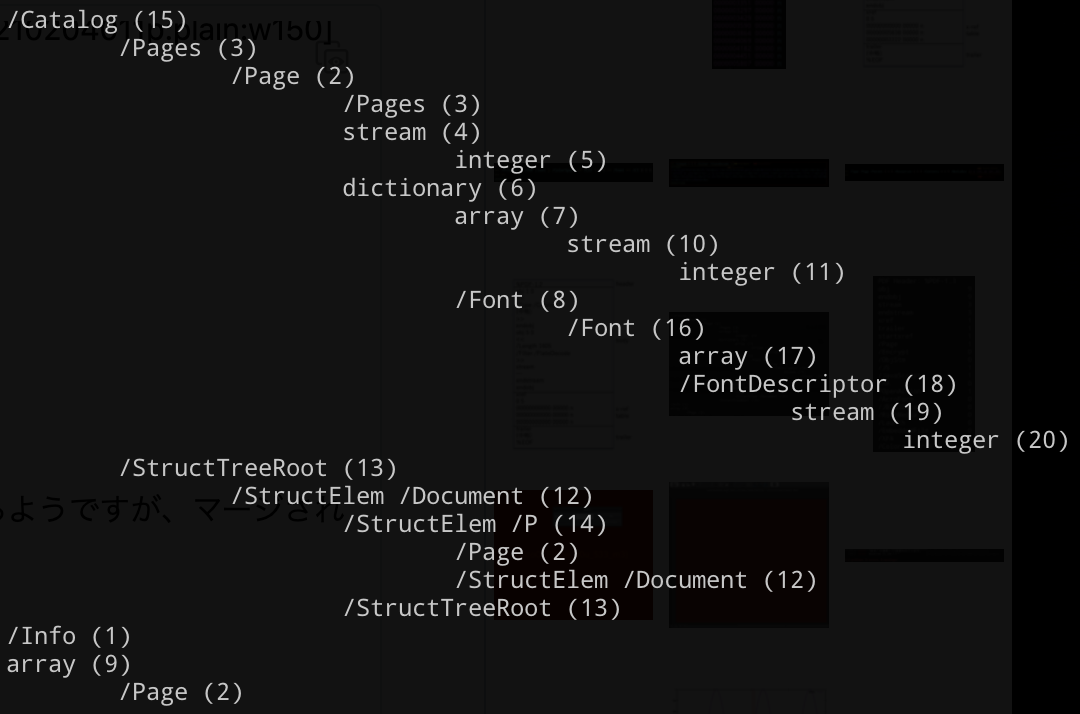

tree表示の方を見てみると、Page(2)はPages(3)、stream(4)、dictionary(6)を参照しているようです。テキストエディタで開いた方を見てみると、「3 0 R 6 0 R 4 0 R」と参照関係が書いてあります。tree表示と一致しています。
tree表示の出力を変更する
PDFの階層構造を扱う際にpeepdfは非常に強力なツールですが、出力行数が大きい時に途中で出力が止まる(キー入力待ち状態になる)といった問題があります。
テキストファイルに出力したい時に不便なので修正します。少々雑ですが、以下の修正を行うと解消できます。
- peepdf/PDFConsole.py 4293行目
- limit = int(self.variables['output_limit'][0]) + limit = 10000000 #とにかく大きな数字
これで多少扱いやすくなります。
疑わしいファイルの検知
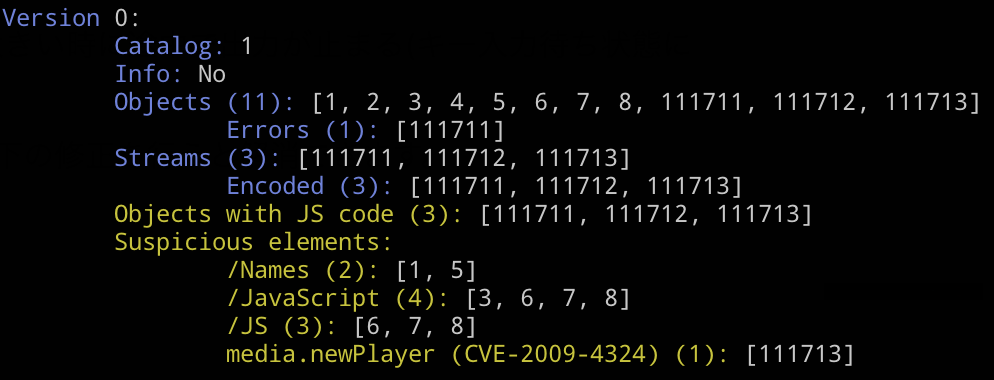
peepdfでは面倒な設定なしで疑わしいファイルを検知する機能があります。オプションなしで実行した際の統計情報に、疑わしいインダイレクトオブジェクトがあった旨が書かれます。
PDFマルウェアで試してみると、こんな感じになります。CVEまで特定されていますね。
おわりに
ツールを使うことで、より深くPDFを解析することができそうです。
今回紹介したツールにはまだ紹介しきれていないオプションもあったりするので、どこかで記事をかけたらいいなと思います。
次のPDFにまつわる記事はまだ未定ですが、pdf-parserの出力を読み込んで自作プログラムで扱いやすくする話なんかを書こうと思います。需要がどこにあるのかはわかりませんが。
参考文献
マルウェア解析者向け: 疑わしい PDF を解析する Python ツール - 拡張頭蓋 | Extended Cranium