好きな温泉の話
この記事はImaizumi Lab Advent Calendarの4日目です。諸事情により10日遅刻しました。*1
今回は(も?) ゆるい記事です。SecHack365イチの温泉好き(自称)の私が、よかった温泉について語っていこうと思います。
順番はお勧め順です。
乳頭温泉
泉質にこだわるならここはおすすめです。ここは夏と冬で違った景色を見せてくれるので両方行くのがお勧めです。
冬は雪が降る中温泉に入るのがとても良いです。
ただし、冬季は休業している温泉があるため全ての温泉を巡ることができません。全ての温泉に入りたいなら夏、雪景色を満喫したいなら冬ですね。
鶴の湯で食べられる山芋鍋が絶品なのでぜひ食べてください。
酸ヶ湯温泉
ヒバ千人風呂が有名です。ここも泉質が良いです。混浴ですが湯着を購入することができるので、抵抗がある方でも多少は大丈夫かと思います。
普通の旅館らしい部屋と湯治棟があるのですが、湯治棟の方にぜひ泊まって欲しいです。
ほったらかし温泉
開放感があって良い露天風呂です。車がないとちょっと行きづらい。
草津温泉の西の河原露天風呂
ゴリゴリの濁ったお湯が大好き人間なので自分の中で草津温泉はそこそこの評価なのですが、西の河原露天風呂は温泉に向かうまでの道の雰囲気が非常によかったです。非日常感があります。
風呂はかなり広めなので、他の人を気にせずにのんびりすることができます。
おわりに
あとはSecHack365'18の山形回で入った温泉もよかったです。*2
良い温泉を思い出したら追記していこうと思います。
PDFを覗いてみよう(ツール編)
この記事はImaizumi Lab Advent Calendarの9日目です。
なお記事の投稿は13日の模様。
更新履歴
2020/12/13 投稿後にpeepdfのマルウェア検知機能について書き忘れていたことに気づいたので追記
はじめに
前回に引き続き、PDFの内部構造を見ていきます。
前回の記事はこちらです。
今回のトピックは、PDFを解析するのに便利なツールの紹介です。
前回の記事でPDFの構造がどうなっているかをみていきました。構造を詳しく見ていくと面白そうですが、PDFのインダイレクトオブジェクトの参照関係を手作業で探ったり、出てくるキーワードをカウントしていくのは大変ですよね。そこでツールの出番です。
紹介するツールは全てPython製で面倒なインストールなど不要なので、是非お手元のPDFで試してみてください。
(Pythonは2系と3系の両方が使える必要があります。peepdfが2系でしか動かないためです)
PDFiD
DidierStevensSuite/pdfid.py at master · DidierStevens/DidierStevensSuite · GitHub
PDFの特定のキーワードを抽出し、数を表示してくれるツールです。
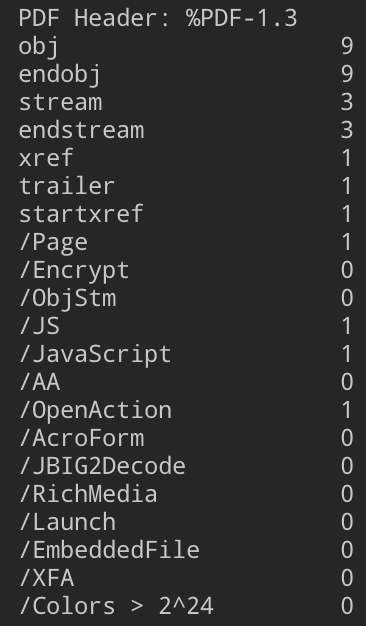
PDFの機能を悪用したマルウェアでは特定の機能が使われることが多く(/JavaScript、/OpenActionなど)、このツールで調べることでそれらの機能が使われているかを簡単にチェックすることができます。
pdf-parser
DidierStevensSuite/pdf-parser.py at master · DidierStevens/DidierStevensSuite · GitHub
非常に高機能なPDFパーサです。
先ほど紹介したPDFiDと似たような統計出力機能もあります。*1
実行してみる

オプションなしで実行すると、
- オブジェクト番号と世代番号
- インダイレクトオブジェクトの種類
- 参照関係
- ディクショナリの内容
が表示されます。
ファイル全部ではなく特定のインダイレクトオブジェクトだけを見たい場合は、「-o n (nはオブジェクト番号)」と指定します。
その他できること
-yオプションでYARAルールを引数に取ることで、ルールに基づきPDFが悪性かどうかを検知できます。*2
-sオプションで「-s hogehoge」のように指定すると、hogehogeを含むオブジェクトを抽出できたりします。
ちょっと面白いのは、-gオプションを用いるとパース対象のPDFファイルを生成するPythonプログラムを生成します。どこで使うのかはちょっとわかりませんが...
peepdf
Pythonのバージョンが2系でしか動かないため注意が必要です。*3
特定のライブラリがないと怒られるかもしれませんが、ここに書いてあるオプションはそれらのライブラリなしで実行可能なので、無視しても大丈夫です。*4
実行してみる

オプションなしで実行すると、統計情報が表示されます。
tree表示
python peepdf.py hoge.pdf -f -C tree
上記のコマンド*5で、参照関係を表した木構造を表示させることができます。カッコの中はオブジェクト番号です。試しにオブジェクト番号が2のインダイレクトオブジェクトを、出力したtreeとファイルデータの両方で見てみましょう。
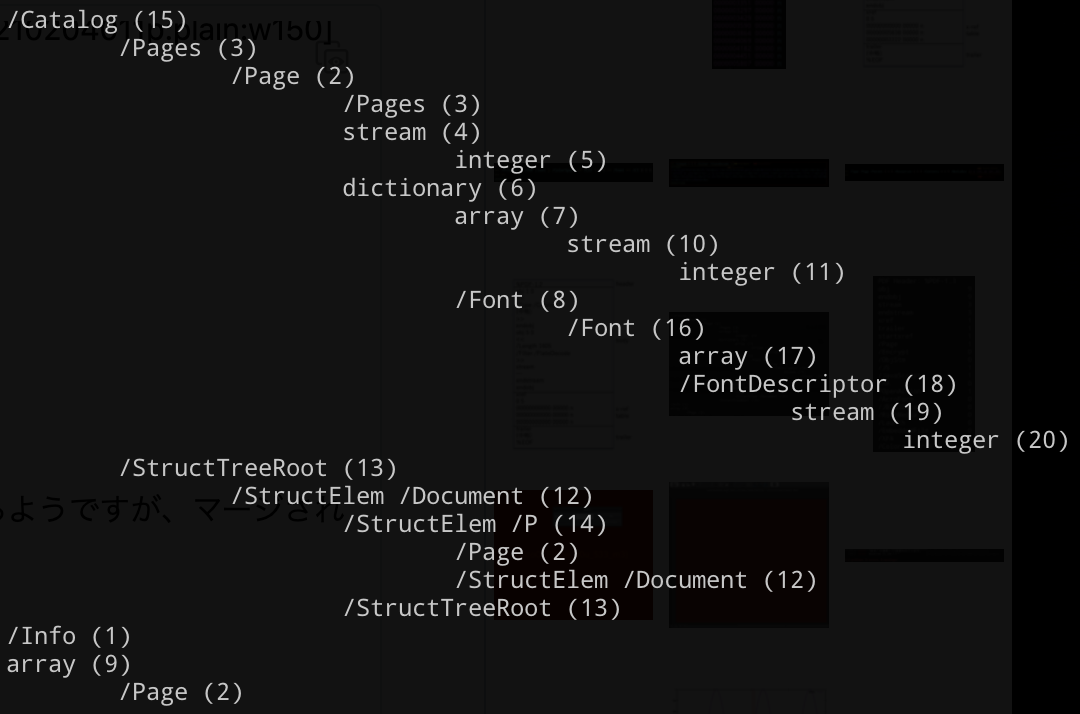

tree表示の方を見てみると、Page(2)はPages(3)、stream(4)、dictionary(6)を参照しているようです。テキストエディタで開いた方を見てみると、「3 0 R 6 0 R 4 0 R」と参照関係が書いてあります。tree表示と一致しています。
tree表示の出力を変更する
PDFの階層構造を扱う際にpeepdfは非常に強力なツールですが、出力行数が大きい時に途中で出力が止まる(キー入力待ち状態になる)といった問題があります。
テキストファイルに出力したい時に不便なので修正します。少々雑ですが、以下の修正を行うと解消できます。
- peepdf/PDFConsole.py 4293行目
- limit = int(self.variables['output_limit'][0]) + limit = 10000000 #とにかく大きな数字
これで多少扱いやすくなります。
疑わしいファイルの検知
peepdfでは面倒な設定なしで疑わしいファイルを検知する機能があります。オプションなしで実行した際の統計情報に、疑わしいインダイレクトオブジェクトがあった旨が書かれます。
PDFマルウェアで試してみると、こんな感じになります。CVEまで特定されていますね。
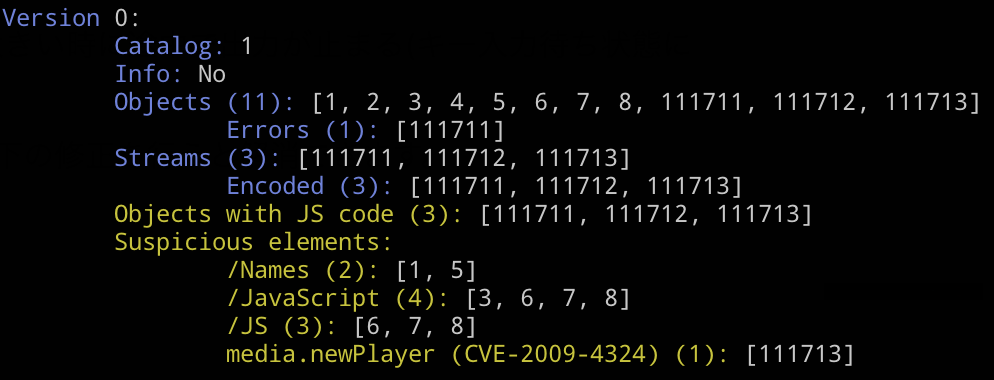
おわりに
ツールを使うことで、より深くPDFを解析することができそうです。
今回紹介したツールにはまだ紹介しきれていないオプションもあったりするので、どこかで記事をかけたらいいなと思います。
次のPDFにまつわる記事はまだ未定ですが、pdf-parserの出力を読み込んで自作プログラムで扱いやすくする話なんかを書こうと思います。需要がどこにあるのかはわかりませんが。
参考文献
マルウェア解析者向け: 疑わしい PDF を解析する Python ツール - 拡張頭蓋 | Extended Cranium
PDFを覗いてみよう(入門編)
この記事は、Imaizumi Lab Advent Calendar 8日目です。
もはや今日が何日なのかわからなくなってきました。
はじめに
騙されたと思って、お好きなテキストエディタ(vimとかemacsとか...)でPDFを開いてみてください。
きっとこのようなコードが表示されたはずです。


ところどころですが、PDF、Length、Filterなどといった人間に理解できる単語が出てきていますね。
意外とPDFって読めるんだと思いませんか? 構造について詳しくなれば出てくる文字列がどういう意味なのかわかるようになりそうです。
実はPDFの構造の仕様は公開されており、無料で読むことができます。
- PDFリファレンス
https://www.adobe.com/content/dam/acom/en/devnet/pdf/pdf_reference_archive/pdf_reference_1-7.pdf
PDFの概略をつかむのに良いですが、大変なことに1310ページもあります。
PDFの構造に興味を持っても、さすがにこれを全部読むのは厳しいですよね。
というわけで本稿では初めてPDFの構造に触れる人を対象とし、PDFリファレンスの第三章(Syntax)を中心に、PDFの簡単な仕様について見ていきたいと思います。*1
上から順番に覗いてみる
PDFの構造は上から以下のようになっています。是非皆さんもお手元にファイルを用意して覗いてみてください。
(注意:PDFはなるべく中身がシンプルなもの(文章がHello, worldだけとか)を用意した方がいいと思います。何回も更新しているファイルだと追加更新という仕組みのせいで、特定の構造が複数回出てきたりするため本稿の説明と合わなくなります。追加更新については本稿では扱いません)

ヘッダ
PDFの一番先頭にあります。「%PDF-(数字)」となっている部分がヘッダです。数字部分はPDFのバージョンを表しています。
ボディ
インダイレクトオブジェクト(名前付きオブジェクト)と呼ばれるものが上から順番に並んでいます。
インダイレクトオブジェクトの説明をする前に、まずオブジェクトについて説明します。オブジェクトとはPDFを構成する要素で、
- Boolean
- Number
- String
- Name
- Array
- Dictionary
- Stream
- The null object
の8種類が存在します。
エディタでPDFを開いた時に表示されているものは、オブジェクトの集合体です。


あるオブジェクトの中には別のオブジェクトを含むことができます。ArrayとNumberの例だとわかりやすいですね。
さて、本題に戻ります。インダイレクトオブジェクトとは、他のオブジェクトから参照されるようにラベル付けされたオブジェクトのことです。

画像で説明すると、6 0 obj ~ endobj までがインダイレクトオブジェクトです。
インダイレクトオブジェクトはラベルとしてオブジェクト番号と世代番号を持ちます。この二つにより、インダイレクトオブジェクトを特定することができます。
上記の画像だと、6がオブジェクト番号で0が世代番号です。オブジェクト番号はオブジェクトを表す番号です。世代番号はオブジェクトが更新された際に変更される可能性がある番号です。
ところで、画像中に「7 0 R」「8 0 R」といった文字列がありますね。これは、このオブジェクトが7 0 objと8 0 objを参照していることを指しています。
クロスリファレンステーブル
PDFをビューワで見ているとき、ページの途中からでも瞬時に読み込まれますよね? これを実現しているのがこのクロスリファレンステーブルです。
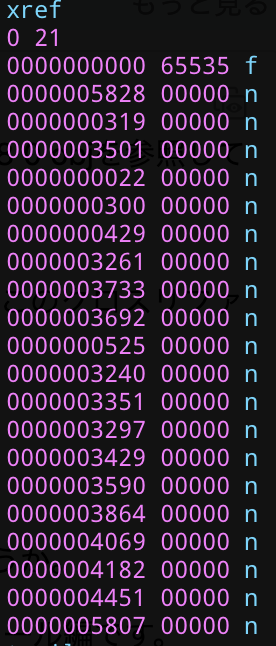
画像中の、0 21はオブジェクト番号0-20までの情報が入っていることを示しています。(オブジェクト番号が0のインダイレクトオブジェクトなんてないじゃないかと言われそうですが、これは特殊なインダイレクトオブジェクトのことで、常に使われません)
その下の「xxxxxxxxxx yyyyy n」となっているものは、インダイレクトオブジェクトがファイルの先頭からどの位置にあるかを示しています。画像の場合だと、上から順番にオブジェクト番号0からの情報が入っています。
xxxxxxxxxxが先頭からのオフセット、yyyyyが世代番号、最後のnは使用中のインダイレクトオブジェクトであることを指します。(最後のnがfになると未使用であることを指します)
トレイラー
クロスリファレンステーブルと特殊なオブジェクトを素早く読み込むためのものです。
上から順番にtrailer(キーワード)、トレイラーディクショナリ、startxref(キーワード)、xref(キーワード)の先頭までのオフセット、%%EOFとなっています。

おわりに
PDFをエディタで覗いてみると、意外と人間にも理解できる構造をしていることが分かったのではないでしょうか。
PDFに関してはネタがまだいくつかあるので、追々紹介していこうと思っています。次回は(多分)PDFの解析ツール編です。
参考文献
PDFの仕様書を読む 第24回 3.4.5 Incremental Updates : log log log
https://www.adobe.com/content/dam/acom/en/devnet/pdf/pdf_reference_archive/pdf_reference_1-7.pdf
*1:PDFの最新の規格はPDF2.0ですが、リファレンスがPDF1.7までのものなので1.7までの仕様で解説します。ここで書いていることは変更はないはずです
色彩検定2級に合格した
この記事はImaizumi Lab Advent Calendarの7日目です。
1-3日目まで私が連続して書いてきました。4日目、6日目はただいま準備中です。
5日目は研究室の先輩が書いてくださりました。ありがとうございます。
なぜ7日目だけ先になったかというと、実は事前に準備していたからです。事前準備大事。
はじめに
11/8に色彩検定2級を受験し、無事合格しました。
どんな勉強をしたかなどまとめていきます。
なぜ受けたのか
趣味も仕事も学業も全てコンピュータ系なので、知識を広げるという意味でもたまには全く違うことをしたいなと思ったからです。
なぜ3級を飛ばして2級なのかというと、3級は簡単すぎると感じたのと、2級で出てくる話題のうち分光分布、分光視感効率、錯視などの話は学部と大学院の授業で学んでいたためです。
勉強法
二週間前くらいから参考書を読んでいました。*1
基本的には、
- 二日に一回本を通読する(本は前半は参考書、後半は公式テキスト)
- 直前の平日に過去問を解く(3級のものも)
という流れでやっていきました。
これくらいやれば十分だと思いますし、これほどやらなくても合格できるとは思います。
最初の一週間にメインで使っていた参考書はこれです。
全ての内容が問題形式だったので取り組みやすかったです。
本当はこの参考書だけで最後までいこうと思ったのですが、過去問の形式に慣れておきたかったので受験直前に公式テキストと公式過去問集も追加しました。
(ただし内容が受験直前に改訂されていたため、過去問には公式テキストに載ってない内容がありました...)
個人的には公式テキスト+問題集だけでよかったかなと思っています。
ちなみに合格者受験番号一覧を見ましたが、合格率は7,8割くらいのようでした。普通に勉強していれば十分合格可能なようですね。
おわりに
文字通り世界が色付いて見えるので、色彩検定おすすめです。
実用的な知識から雑学的な知識まで得られるので知的好奇心が満たされるのではないかと思います。私はかなり満たされました。
2級を取ったなら1級もチャレンジしろと言われそうですが、1級は受けないと思います。受験料が高くつくのと、二次試験が入ってきて大変になるので...
なお色彩検定には1-3級の他にUC級というユニバーサルデザインに特化した級が存在します。スライドとか作る機会が多いので、これは受験するかテキストを買って勉強してもいいかなと思っています。
*1:ちなみにその三週間前くらいに受けた情報処理安全確保支援士は全く過去問をやっていません。本業...
CLIP STUDIO PAINTでCTFの問題を解いてみる
この記事はImaizumi Lab Advent Calendarの3日目です。
はじめに
本日の記事は小ネタ記事です。
皆さんはCLIP STUDIO PAINT(以下クリスタ)を使ってらっしゃいますか?
簡単に説明すると、イラストを描くのによく使われているペイントソフトです。
偶然にも本日、アップデートでPhotoshopのブラシをそのまま読み込んで使えるようになることがTwitterでトレンドになっていました。それくらいユーザ数が多いペイントソフトです。
本題です。画像としてステガノグラフィが埋め込まれているケースでは、2値化してみたりRGBのバランスをいじったりすることで文字が浮かび上がるケースがあります。
試しに一つ問題をクリスタで解いてみます。
now you don't(PicoCTF 2018)
画像ファイルが渡されたので、クリスタで開いてみます。
真っ赤ですね。
試しにレイヤー>新規色調補正レイヤー>階調化 で何か出てこないか見てみます。
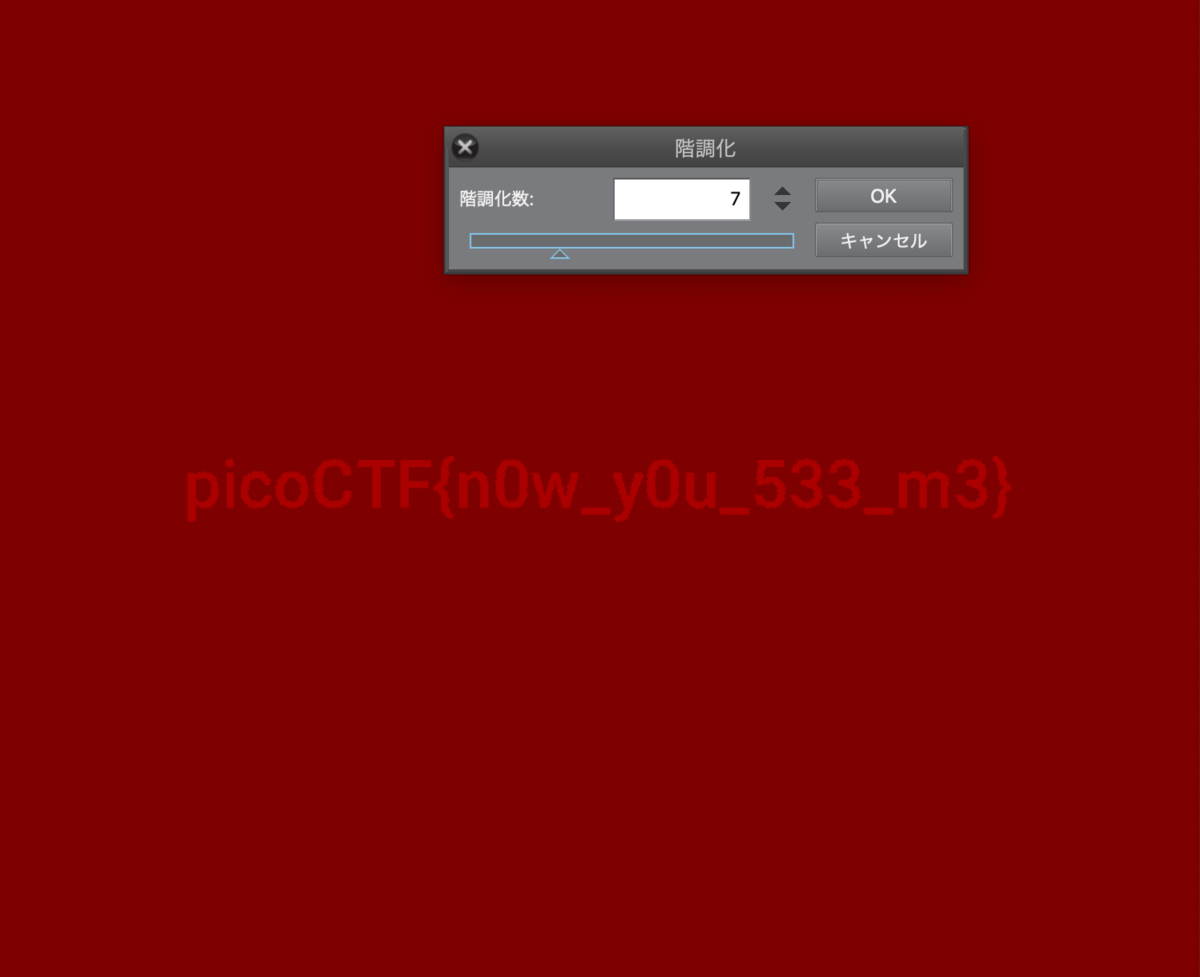
こんな感じでフラグが表示されました。
ステガノグラフィ探しに有用と思われるフィルタ
クリスタには先ほど使用した階調化の他にも、いくつか色調を補正するフィルタがあります。
今回は、どのようなフィルタがステガノ問に使えそうか検討しピックアップしてみました。
2値化
黒と白の二段階に色調を変更します。人間の目でわかりづらい色の差でフラグが埋め込まれている場合に有効ではないかと思います。
階調化
色味は保ったまま、指定した数の階調に色調を変更します。このフィルタで解ける問題は2値化でも解けるのですが、階調化は段階が2-20しかないため、こちらの方が早く問題を解けるかもしれません。
レベル補正
RGBの各色のレベルを補正できます。例えば赤色成分を消したらフラグが現れるといったケースで有効と思われます。
良さげな例題が見つからなかったので例が見せられないのが残念です。
おわりに
今回はクリスタでステガノ問に使えそうなフィルタを紹介してみました。
クリスタはイラストや漫画を描くだけではなくCTFでも大活躍してくれそうですね。
とはいえ、うさみみハリケーンなど他のツールを使った方が絶対にいいと思います。
以上小ネタでした。おしまい。
LaTeXとVSCodeとtextlintで作る論文執筆環境
この記事はImaizumi Lab Advent Calendarの2日目です。
はじめに
論文執筆シーズンがやってまいりました。
というわけでこの記事では、初めて論文を書く後輩に向けて私の執筆環境を紹介できればと思います。
私自身執筆環境は試行錯誤している真っ只中なので、いい環境が作れたらまた更新します。
VScode+LaTeX
Macの場合、
brew cask install mactex brew cask install visual-studio-code
でインストールできます。
流れとしては、
となります。
この記事の通りに進めています(素晴らしい記事をありがとうございます!) qiita.com
多分上記の記事の通りにやればエラーが出ないはずなのですが、筆者の環境では実行時にコマンドがないと怒られてしまうため(which platexとかしたらちゃんとパスが通っているのに...)、応急処置としてフルパスで指定しています。
こんな感じです↓
[~/.latexmkrc] $latex = '/usr/local/texlive/2020/bin/x86_64-darwin/uplatex %O -synctex=1 -interaction=nonstopmode %S'; $pdflatex = '/usr/local/texlive/2020/bin/x86_64-darwin/pdflatex %O -synctex=1 -interaction=nonstopmode %S'; $lualatex = '/usr/local/texlive/2020/bin/x86_64-darwin/lualatex %O -synctex=1 -interaction=nonstopmode %S'; $xelatex = '/usr/local/texlive/2020/bin/x86_64-darwin/xelatex %O -no-pdf -synctex=1 -shell-escape -interaction=nonstopmode %S'; $biber = '/usr/local/texlive/2020/bin/x86_64-darwin/biber %O --bblencoding=utf8 -u -U --output_safechars %B'; $bibtex = '/usr/local/texlive/2020/bin/x86_64-darwin/upbibtex %O %B'; $makeindex = '/usr/local/texlive/2020/bin/x86_64-darwin/upmendex %O -o %D %S'; $dvipdf = '/usr/local/texlive/2020/bin/x86_64-darwin/dvipdfmx %O -o %D %S'; $dvips = '/usr/local/texlive/2020/bin/x86_64-darwin/dvips %O -z -f %S | convbkmk -u > %D'; $ps2pdf = '/usr/local/texlive/2020/bin/x86_64-darwin/ps2pdf %O %S %D';
[~/settings.json] (略) "latex-workshop.latex.tools": [ { "name": "Latexmk (XeLaTeX)", "command": "/usr/local/texlive/2020/bin/x86_64-darwin/latexmk", "args": [ "-f", "-gg", "-pv", "-xelatex", "-synctex=1", "-interaction=nonstopmode", "-file-line-error", "%DOC%" ] }, { "name": "Latexmk (upLaTeX)", "command": "/usr/local/texlive/2020/bin/x86_64-darwin/latexmk", "args": [ "-f", "-gg", "-pv", "-synctex=1", "-interaction=nonstopmode", "-file-line-error", "%DOC%" ] }, { "name": "Latexmk (pLaTeX)", "command": "/usr/local/texlive/2020/bin/x86_64-darwin/latexmk", "args": [ "-f", "-gg", "-pv", "-latex='/usr/local/texlive/2020/bin/x86_64-darwin/platex'", "-latexoption='-kanji=utf8 -no-guess-input-env'", "-synctex=1", "-interaction=nonstopmode", "-file-line-error", "%DOC%" ] }, { "name": "Latexmk (LuaLaTeX)", "command": "/usr/local/texlive/2020/bin/x86_64-darwin/latexmk", "args": [ "-f", "-gg", "-pv", "-lualatex", "-synctex=1", "-interaction=nonstopmode", "-file-line-error", "%DOC%" ] } ], (略)
textlint
textlintは日本語文章の校正ツールです。
主に技術文書として相応しくない表現や、単語の用法のミスなどを指摘してくれます。

インストールは以下の通りです*1。texファイルのあるディレクトリで実行してください。
事前にnpmコマンドが実行できる状態にしておいてください。(Node.jsについては本稿の範囲外とします)
npm install --save-dev textlint npm install --save-dev textlint-filter-rule-comments npm install --save-dev textlint-rule-preset-ja-spacing npm install --save-dev textlint-rule-preset-ja-technical-writing npm install --save-dev textlint-plugin-latex2e
次に定義ファイルを作ります。
./node_modules/.bin/textlint --init
で.textlintrcが作られます。
筆者の.textlintrcはこんな感じです。一部のルールを無視するようにしています。
[.textlintrc]
{
"plugins": [
//latex用プラグインを有効化 これは絶対必要
"latex2e"
],
"rules": {
"preset-ja-spacing": true,
"preset-ja-technical-writing": {
"no-doubled-joshi": false,
"ja-no-mixed-period": {
"periodMark": ".",
},
"max-kanji-continuous-len": false,
"sentence-length": false,
},
"preset-ja-engineering-paper": {
"prh": false,
}
},
"filters": {
"comments": {
// enable comment directive
// if comment has the value, then enable textlint rule
"enablingComment": "textlint-enable",
// disable comment directive
// if comment has the value, then disable textlint rule
"disablingComment": "textlint-disable"
}
}
}
textlintを無視する
%textlint-disable (無視したい文章) %textlint-enable
でいけます。表などの前後で指定してやるといいでしょう。また、特定のルールのみを無視することもできます。
GitHub
端末は締め切り直前に壊れるものと相場は決まっています。リモートにしっかり保存しておきましょう。
GitHubに作成する場合は必ずプライベートリポジトリで作成してください。
gitの使い方やGitHubの使い方は本稿の範囲外とします。
.gitignore
gitの管理から外したいファイルを書いておきます。私のケースだとこんな感じです。
node_modules/* *.dvi *.aux *.fdb_latexmk *.fls *.log *.pdf *.synctex.gz *.pptx .DS_Store *.eps *.png
画像は基本的には管理から外していますが、すぐに作れない画像なんかは
git add -f hogehoge
でaddしてgitの管理下に置くこともあります。
git hook
リポジトリにpushする前にtextlintのチェックが通るかを検査します。通らなければpushは実行されません。
pushが実行されるかどうかにこだわりがなければ、Github Actionsを利用してもいいと思います。無料枠を使い潰すことはおそらくないと思うので...
cp .git/hooks/pre-push.sample .git/hooks/pre-push
とコピーし、以下のように追記します。
[.git/hooks/pre-push] #句読点を変更 sed -e 's/、/,/g' main.tex > main2.tex sed -e 's/。/./g' main2.tex > main3.tex cp main3.tex main.tex rm main2.tex main3.tex #textlintを実行 ./node_modules/.bin/textlint main.tex #問題なかった時のみpushが実行される exit $?
git hookを無視する
git hookを無視したい時には
git push --no-verify
でいけます(本稿のようにpush前に実行するようになっている場合)。
git hookの意味が全くないですが、テストを通さずにpushしたい時もあると思うので。
textlintでエラーが出た場合
textlintでTeXをチェックしている時、
'b' is not iterable (うろおぼえです)
のようなエラーが出てtextlintが動かないことがたまにあります。
この場合は\begin{comment}-\end{comment}がないかを確認してみてください。
私の環境で動かなかった時はコメントが原因で、削除すると動きました。
(2020/12/29追記)
textlint-plugin-latex2eのコントリビュータのkn1chtさんが修正されて、v1.0.4以降では'b' is not iterableは出なくなったようです。
おまけ:その他VSCodeのおすすめプラグイン
TODO Highlight
TODO:、FIXME: と入力したらハイライトしてくれます。
コメント部分がわかりづらいので入れておくといいと思います。

*1:グローバルインストールしてもいいのかも
RISC-Vのエミュレータを作っている
この記事はImaizumi Lab Advent Calendarの1日目です。
更新履歴
2020/12/2 誤字を修正
はじめに
ゼミでModern Computer Architecture and Organizationという本をやっていて、RISC-Vについて解説した章の担当になったので余興としてRISC-Vのエミュレータを作りました。
この記事は特に目的はないのですが、強いていうならRISC-Vのエミュレータを作りたい人がどうすれば最低限の実装ができるのかを示したいと思います。
記事執筆時点での最新のコミットはこちらです。 github.com
記事執筆時点では、基本命令セットのRV32Iをほぼ実装しています。ほぼと書いているのは、マルチスレッド処理で必要な命令を実装していないからです。(現状はシングルスレッドの実装のため)
注意
実装の正しさは保証しません。現時点でバグがあることを確認しています。
また、筆者はエミュレータやCPUには明るくないので、誤りを含んでいる可能性があります。
最低限の実装の概略
まずは実行する機械語をメモリ(として使う配列)に格納します。そしてプログラムカウンタを用意し、0にセットします。
CPUはフェッチ→デコード→実行のサイクルを繰り返します。
- フェッチ...バイナリを4byteずつ取り出す。リトルエンディアンに注意
- (この間でプログラムカウンタがインクリメントされる)
- デコード...どの命令に当たるのか、指定されたレジスタは何番かなどを解釈
- 実行...対応する命令を実行
これをひたすら繰り返す*1処理を書けばokです。
デコードは、opcode(全てのフォーマットの先頭から7bit)でフォーマットが決まるのでそれを元にrd, rs1, immなどの数値を解釈します。
rd, rs1, immなどの用語についてはRISC-Vの仕様書をみてください。
実行はopcodeとfunct3(一部例外あり)を元に実行する命令を決定します。
実行してみる
RISC-Vの公式が出しているテストをとりあえず使っています。
objcopyで機械語部分だけをコピーしたものを作成し、先頭からプログラム中のメモリ(として使う配列)にコピーしていきます。
objcopyはこんなコマンドです。
riscv64-unknown-elf-objcopy -O binary rv32ui-v-xori rv32ui-v-xori.bin
このコマンドを使用するにはRISC-V Toolchainのインストールが必要です。
Macを使っている場合はhomebrew-riscvで入れるのが一番楽で失敗もないかと思います。
テストを完璧に動作させるにはおそらくシステムコールの実装が必要と思われるのですが、そこまでできていないので現状はデバッグでプログラムカウンタとレジスタの中身と命令を表示し、正しく解釈されているかをdumpファイル(riscv-testsの中に入ってます)と見比べてデバッグしています。
本当は現状の実装で動くテストを書きたい。
余力があれば直接ELFファイルを解釈してもいいと思います。私の実装では現状実装していますが、うまく動かないのでobjcopyしたものを動かしています。
参考資料
RISC-V 公式仕様書
riscv.org 基本的にはこれを読みながら実装していくことになります。ただ、これだけだとわかりづらい情報があるので、次に紹介する資料も合わせてみると実装しやすいかと思います。
riscv/riscv-opcodes
RISC-Vの公式が出している、オペコードの一覧表です。 opcodeやfunct3が分かりやすいので、実際に命令を解釈するときにわかりやすいかと思います。
まとめ
意外とエミュレータを作るのは簡単なので、皆さんも是非やってみてください。
*1:無限ループなのでどこかで終了させなくてはならない。私は一旦フェッチしたバイナリが0なら終了させてます